 BMVC'25
BMVC'25
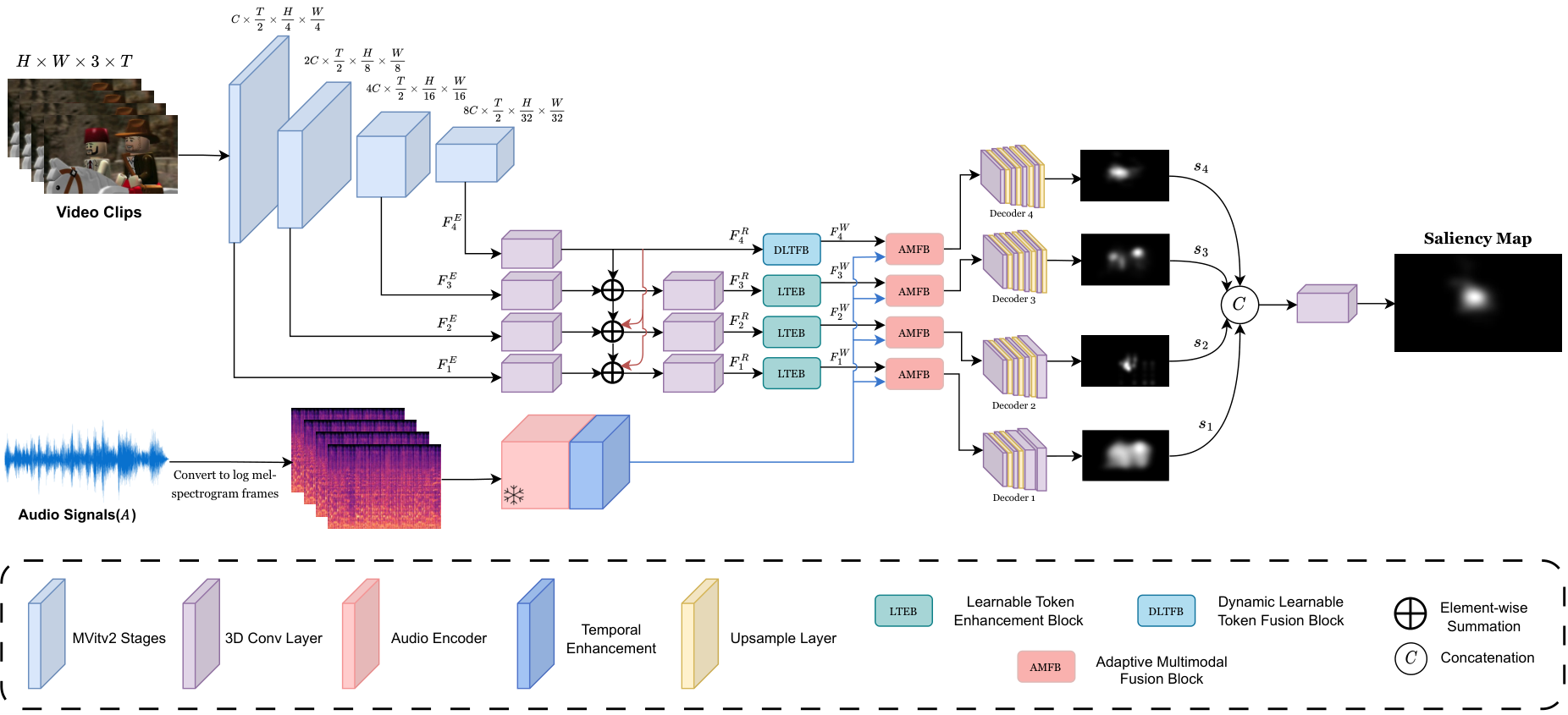
Audio-visual saliency prediction aims to mimic human visual attention by identifying salient regions in videos through the integration of both visual and auditory information. Although visual-only approaches have significantly advanced, effectively incorporating auditory cues remains challenging due to complex spatio-temporal interactions and high computational demands. To address these challenges, we propose Dynamic Token Fusion Saliency (DTFSal), a novel audio-visual saliency prediction framework designed to balance accuracy with computational efficiency. Our approach features a multi-scale visual encoder equipped with two novel modules: the Learnable Token Enhancement Block (LTEB), which adaptively weights tokens to emphasize crucial saliency cues, and the Dynamic Learnable Token Fusion Block (DLTFB), which employs a shifting operation to reorganize and merge features. An audio branch processes raw audio signals, and both modalities are integrated using our Adaptive Multimodal Fusion Block (AMFB). Extensive evaluations on six audio-visual benchmarks demonstrate that DTFSal achieves state-of-the-art performance while maintaining computational efficiency.